
从标题上也可以看到,是 Chat with your data,所以首先是文件的导入。可以将本地的文件用 langchain.document_loaders 里的 各种文件对应的 Loader 读进来。毕竟已经可以用 API 了,所以当即在学课程的时候就动手跑了。跑完再从头到尾串一遍,加深印象。
例如:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/Users/fang/Documents/Me/简历/2023 summer/resume.pdf")
pages = loader.load()loader2 读了一篇 论文进来:

甚至也可以用它来读 YouTube 、github (WebBaseLoader)和 notion 导出的文件。因此知道思路之后,当你想读什么文件,就可以去搜对应的包。

而就在 7 月 的第二个星期,ChatGPT 的 CodeInterpreter 也支持了文件上传,可以支持用代码进行文件读取,然后代码分析。于是 langchain 的一切努力似乎都成了为 ChatGPT 开路。
不过,这也不妨碍我们先了解 langchain 对使用者痛点的解法(by using Modular and Components combination)。

有很多种 text_splitter,功能上实现的都是 分割 文本,切割的思路不同而已。模块名字大多见名知义。名字里的关键词是什么,分割的依据就是什么,把单词看成什么来区分。
chunk_size 是每条 piece 的长度,chunk_overlap 是在切割的时候,当前的 piece 和上一条 piece 重合多少字符。 Recursive 的使用更接近这两个参数的使用,而 CharacterTextSplitter 的分法则不是很直观的看得出来 chunk_size 的作用,一定要在切割的时候, chunk_size 才起作用。



也就是说这里的 separators 设置会影响分割结果。
TokenTextSplitter,把文本里的内容尽可能按照 token 去划分:

MarkdownHeaderTextSplitter,把文本的内容按照 Markdown 级别去分割:

Embeddings
接触过自然语言处理的同学一定不陌生。把自然语言文本编码成向量的过程就叫 embedding。
用 OpenAEmbeddings 进行问题的 embedding,同时用 np 的点积来计算相似性。

用 Chroma 来存 embeddings。


根据问题,vectordb.similarity_search(k=3) 会返回 3 个和问题最相关的文本。
vectordb.persist() 保存。
但你并不是总是想要最相似的片段。因为有可能返回的前两个和问题最相似的文本内容是同一段,或者相邻句子,那么它们含有的信息量就没有稍微不同的句子信息量大。
前两个和最后两个都来自于同一块文本:

Maximum marginal relavance 就是解决这个问题的。
- 先查询向量数据库;
- 找到 ftech_k 个最相似的回答;
- 在这些回答里找到 k 个最不同的。【尽可能 兼听】


但就是有点“non-auto”,于是dangdang~: Retriever 来了!
我们希望它可以自己找到自己适合的 metadata。而巧的是,向量数据库天然地就支持 metadata filters,所以这并不需要新的数据库或索引。
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
可以看到 retriever.get_relevant_documents(question) 通过问题自动找到了对应的文档。
那么你可能会发现,这种搜索是基于所有文档搜索的。那么 LLM 嘛,超大语言模型,面临的文本多了以后,搜索效率必然降低。
所以有一个压缩后再找的技巧:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor 

这里的 search_type 可以制定成前面的 mmr。
也可以再融入 不同的 retriver 方法:
SVMRetriever 和 TFIDFRetriever。

详细见:https://python.langchain.com/docs/modules/chains/popular/vector_db_qa
RetrievalQA 是结合了 定位文档回答问题的 retriever,is a chain for question-answering against an index.
然后这些也可以和 图数据库结合,就比较有意思了。在公司的时候觉得 bom 如果跟 图数据库结合会非常直观。痛在自己对图数据库接触不多。之前 ZH 哥也说这个对银行也是有帮助的。
大概是因为大家都喜欢看图片多过文本吧。

RetrievalQA 结构中,问题作为 query 传递给 向量库,然后 Vector store 提供 k 块 相关的文档,然后这些文本和原始的问题,一起传递给 LLM 模型,最后 得到答案。

如上图,融入了 Langchain 入门的 Template 用法。
三种针对大文本的额外的方法,在 RetrievalQA 里用 chain_type 来设置:

- Map_reduce:对每个小块分别进行 LLM,最后再通过一次 LLM 综合判断;
- Refine:第一个小块的 LLM 和第二块文本一起作为第二个 LLM 的输入,直到第 n-1 块的 LLM 结果和第 n 块文本一起得到最后的 LLM 输入,得到结果;
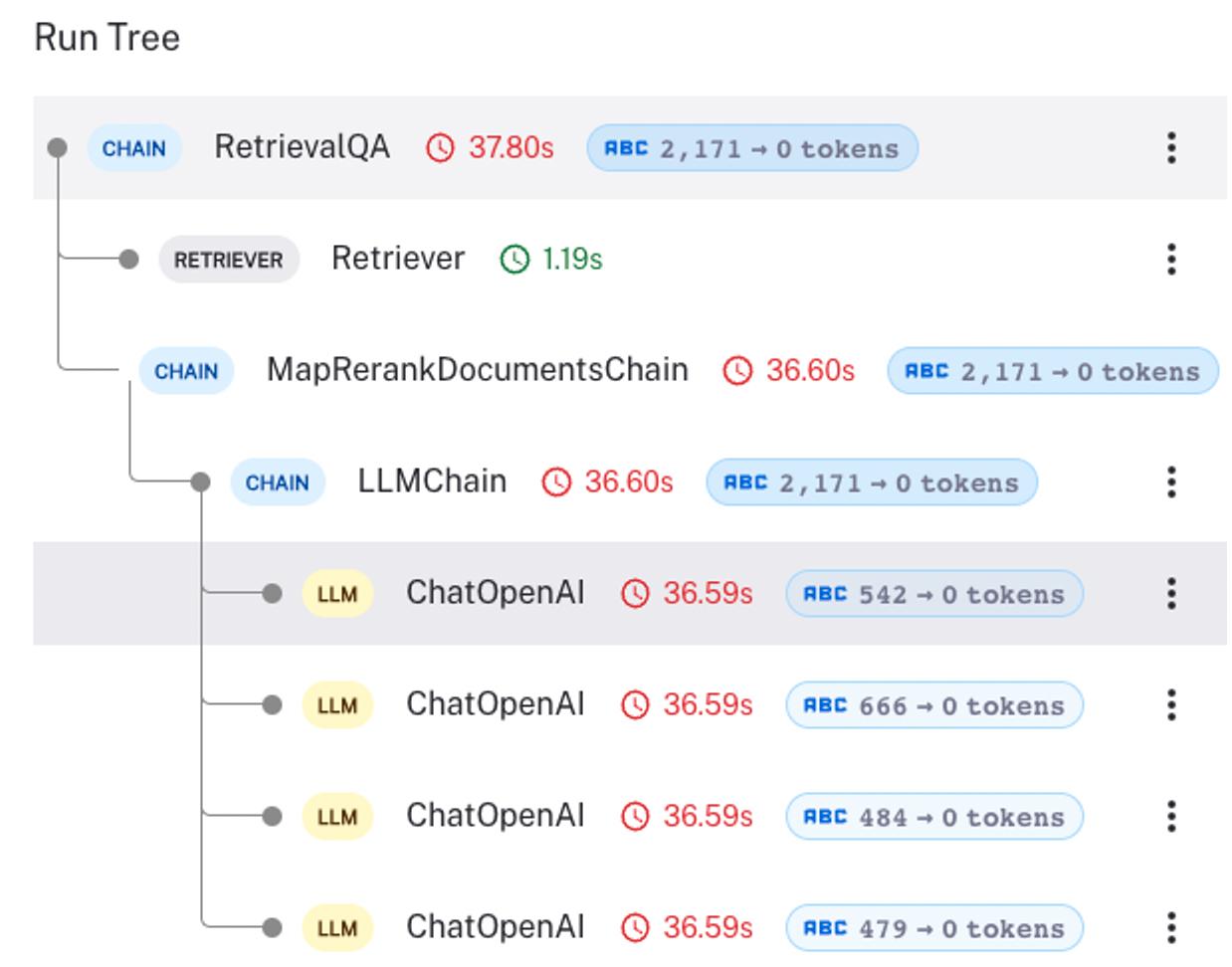
- Map_rerank: 把每个小块进行 LLM,然后打分,选最高分的答案。
接着学到了一个非常炸裂的操作:LangSmith(https://smith.langchain.com/),申请后可以可视化 Chain。申请到 API 后进行环境变量的配置:

三种方法的代码及 LangSmith 监测的截图:
1 chain_type = “map_reduce”



单击右边的内容,可以发现看到那一层在做什么:

2 chain_type = “refine”



可以看到它是每次加点信息,然后让 模型修改答案的。
第二次的 assistant 下面的信息就判断错了,但是后面两次又修正回来了:
第二次:

第三次:

第四次:

这是正在 run 的图标,也好有意思hh。
3 chain_type = “map_rerank”




但是 RetrievalQA 也有不好的地方。它只是每次地回答一个问题,不会记得之前的回答。我们需要一个存储临时对话的服务来使聊天可以在双方之间继续下去。
于是来到了最后一课。
2023 年 9 月 2 日之后,“gpt-3.5-turbo-0301” 要改名为 “gt-3.5-turbo” 。用 ConversationBufferMemory 来存聊天历史,用 ConversationalRetrievalChain 来进行对话。

最后就是代码了。没有设置图片,可能删掉了两行。用 panel 和 param 做了前端窗口。




